
In recent years, Vinay Prasad, a young hematologist–oncologist at Oregon Health and Science University, has emerged as a premier critic of new directions in cancer medicine.
In his view, cancer drugs are aimed at miniscule populations, approved way too easily, and priced too high.
With nearly 21,300 Twitter followers, over 30,000 tweets, a book, and multiple op-eds, Prasad can turn an academic paper into a bestseller—and an obscure point into a rallying cry.
Vinay Prasad is the guy to call.
An argument can be made that his brand is this strong, because most people in oncology’s mainstream, even his biggest detractors, agree with some of his opinions and even make similar points at least some of the time.
This year, the American Association for Cancer Research and the American Society of Clinical Oncology invited Prasad to argue that exaggeration of benefits runs rampant in cancer care today.
At AACR, he was featured at a session titled “Is Genome-Informed Cancer Medicine Generating Patient Benefit or Just Hype?” The scene was repeated at a “meet the professor” session at ASCO.
In fact, when ASCO was planning that session, there was no shortage of candidates for arguing in favor of precision medicine. However, one name clearly stood out for arguing the “con” side—Vinay Prasad.
“He has positioned himself as the iconoclast/John Ioannidis model for oncology. That was how he floated to the top,” said Jeremy Warner, associate professor of medicine and biomedical informatics at Vanderbilt University and ASCO 2018 Annual Meeting Education Committee track leader of the Health Services Research, Clinical Informatics, and Quality of Care track.
Earlier this month, Prasad’s publications formed the intellectual foundation of an editorial, “Easier Drug Approval Isn’t Cutting Drug Prices,” in The New York Times. “Medications are already clearing regulatory hurdles faster than ever, but it’s not clear that people, as opposed to drug companies, are feeling much benefit,” read the lead editorial in the June 8 issue.
Two of Prasad’s opinion pieces—characterized by the Times as “studies”—were cited as key evidence in support of what amounted to a proposal to toughen up FDA’s drug approval standards.
Follow the links, and you will see these papers:
“Comment: Low-value approvals and high prices might incentivize ineffective drug development” in Nature Reviews Clinical Oncology, and
“Perspective: The precision-oncology illusion” in Nature.
According to his website, Prasad is “nationally known for his research on oncology drugs, health policy, evidence-based medicine, bias, public health, preventive medicine, and medical reversal” and “the author of more than 160 peer-reviewed articles and 35 additional letters or replies in many academic journals.”
Prasad, 35, is on Twitter a lot, throwing buckets of cold water on work he describes as “boneheaded,” sometimes resorting to name-calling, and using juicy acronyms. In one Twitter post, Prasad demanded proof on usefulness of aspirin in cancer patients: “RCT or STFU,” he declared. RCT, of course, is an abbreviation for a “randomized controlled trial.”
STFU is “shut the fuck up.”
The tweet, dated June 17, 2016, appears to have been deleted during the writing of this story.
“The community is stubborn”
Critics note that some of Prasad’s most tweetable pieces appear on the opinion pages of peer-reviewed journals and that some of these writings are marred by sloppy arguments and less than perfect use of economics and statistics. While the journals are peer-reviewed, opinion pieces are typically only fact-checked by editors and not sent out to outside experts.
Moreover, these same critics say that they don’t wish to meet Prasad on his turf—Twitter.

“Many physicians, myself included, use Twitter as one tool to help keep current on the academic literature,” said David Hyman, chief of Early Drug Development Service at Memorial Sloan Kettering Cancer Center and Prasad’s debate opponent at AACR. “For some others, peer-reviewed papers or, equally commonly, opinion pieces in these journals, seem almost tailor-made for the next Twitter thread.
“This builds a Twitter following, which in turn drives social media citation metrics, now prominently displayed on most journal’s websites, for the next editorial, and so on. It’s a positive-feedback loop. Speed, reductionism, and sensationalism can be incentivized—sometimes to the detriment of more deliberate and nuanced skepticism that has always served an invaluable role in medical debate,” Hyman said.
“As physicians, we all want the same thing—effective and safe treatments for our patients. The disagreement, to the extent one exists, is really over the best way to get there.”
Prasad’s social media persona is intriguing, said Warner, who debated Prasad at ASCO.
“In terms of social media reach, I don’t know how many of Vinay’s followers are clinicians vs. general public, but his opinions are certainly getting out there way beyond the academic clinical Twittersphere,” said Warner, who directs the Vanderbilt Cancer Registry and Stem Cell Transplant Data Analysis Team. “I was looking at his Twitter feed. It looks like he has made over 30,000 tweets. That is a very time-consuming activity, although not unique amongst the better-known Twitter personas in oncology.”
Recently, in part because of social media stars like Prasad, Warner took a break from Twitter. “It’s hard to get your signal through if other people have such an out-of-proportion presence,” he said. “You see only a few things unless you make it a full-time occupation, which hopefully nobody does. Nevertheless, I still find myself drawn back to Twitter, as it has become a good venue for news in academia.”
The ASCO debate turned out to be a relatively tame affair, Warner said.
“One of the best comments from the audience, which I agree with, is precision oncology is not just about selecting new treatments,” he said. “It’s about helping to realize that some treatments will not work. It’s not about ‘Let’s choose a new drug.’ Sometimes it’s about, ‘Let’s rationally decide to de-escalate or not to do something.’
“Prasad didn’t disagree with that.”
Prasad and Warner agree that post-marketing monitoring of therapies in the US simply doesn’t work. And, of course, it’s clear to everyone that precision medicine chips away at niches of cancer patients, some of whom benefit dramatically.
Some of Prasad’s peers wonder whether building a career on criticism of the prevailing system is a sufficient contribution for an academic oncologist.
Recently, Eliezer Van Allen, an assistant professor and translational scientist at Harvard Medical School and Dana-Farber Cancer Institute, posted a string of responses to one of Prasad’s tweets:
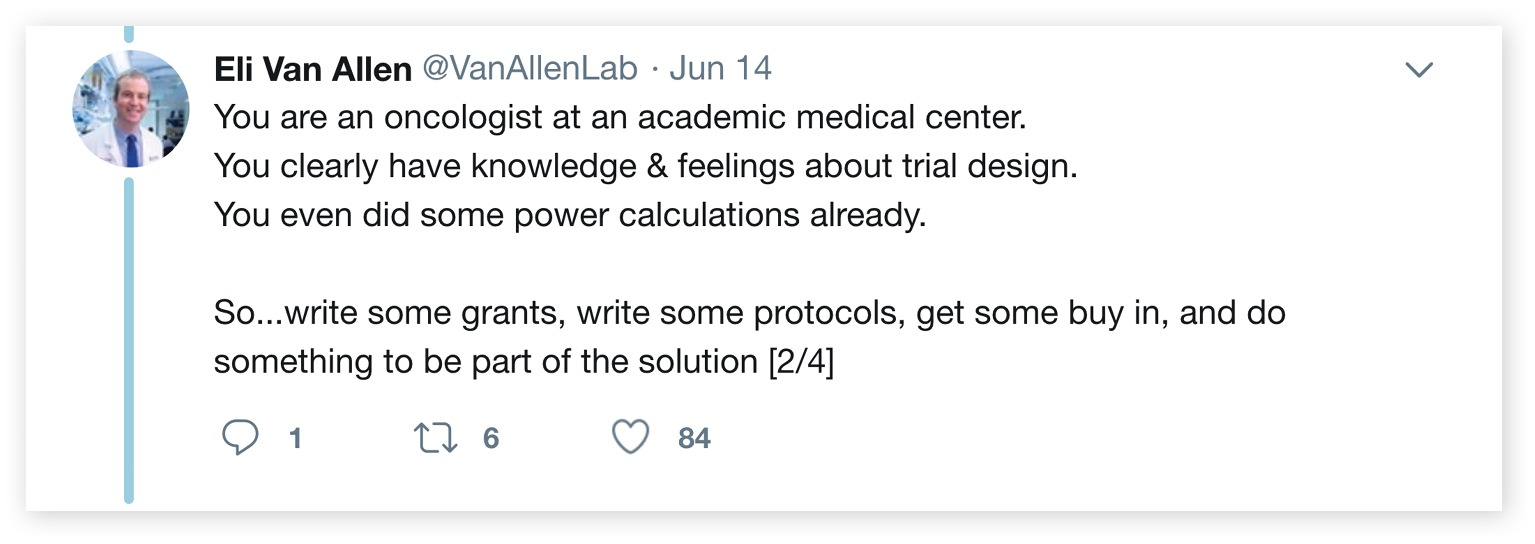
“You are an oncologist at an academic medical center. You clearly have knowledge & feelings about trial design. You even did some power calculations already. So… write some grants, write some protocols, get some buy in, and do something to be part of the solution.
“Just saying the same thing over and over again, whether in social media or in medical literature, ain’t gonna get it done.”
Prasad responded with a string of tweets:
“I have debated this topic at the Washington Post, asco and aacr. The community is stubborn. They think they already know the answer. Cancer centers use this as a sales tactic to bring in patients. No desire to randomize.”
If his Twitter feed is an indication, Prasad is a man in a hurry. On June 21, he tweeted about having uncovered an apparent scandal involving FDA:
“We often discuss the impact of time to drug approval on patient safety What about when the FDA takes 6 MORE MONTHS to restrict the use of HARMFUL drugs than the EMA?”
Prasad had proof of the agency’s slothfulness: the European Medicines Agency’s announcement showed clearly that it restricted Keytruda and Tecentriq in bladder cancer on 01/06/2018, while FDA’s documents showed that its restriction went in effect on 6/20/2018.
Presumably, somebody had informed Prasad that in the UK, where EMA is located, 01/06/2018 stands for June 1, 2018, not Jan. 6. FDA was not six months late.
Prasad deleted the tweet.
The magnitude of benefit from precision oncology
I have been tracking Prasad’s pronouncements for a few years, and—like everyone I know—I agreed with some of what I read, and never looked deeply at his argumentation.
The Times editorial changed that. Prasad’s recommendations were being proposed as a basis for approval of cancer drugs.
“The misguided editorial omits many important pieces, including the need for flexibility in clinical trials, particularly for those with serious illnesses,” Friends of Cancer Research said in a statement. “Additionally, the recommendation that FDA should require two successful clinical trials for any drug is rigid, and in some cases, unethical.
“Arcane rules that tether medicine to a bygone era should not grind our drug approval system to a halt. Such rules will not protect anyone and will only deprive patients of their best chance at recovery.”
With so much at stake for the world’s cancer patients, researchers, and policymakers, it would be important to correct the academic record if Prasad and his colleagues were wrong.
I decided to give Prasad a call.
I had general questions about his thoughts on Twitter, about his views on the FDA standards for drug approval, and—more urgently—I had profound questions about statistical and methodological underpinnings of Prasad’s two opinion pieces cited in the Times editorial.
“Although I tweet about things often, I do not believe I have made any arguments on Twitter that I have not first made in the peer reviewed literature,” Prasad said. “I have some arguments that I purposely do not make on Twitter, because the paper is under review. I’m actually cognizant of that, although I think Twitter is… let’s be honest, why do I use Twitter?
“Number one, I find it fun. I find it fun to use Twitter, it’s enjoyable, it’s interactive, you get to hear from interesting people. I do not use Twitter to debut ideas, I use Twitter to get ideas out that were published in peer reviewed journals.
“I’m pretty sure that everything I’ve said on surrogate endpoints we’ve already published in a couple of papers.”
During our 40-minute chat, Prasad acknowledged that one of his publications was, in fact, mischaracterized in the Times editorial, when it stated that “according to one recent study, targeted cancer therapies will benefit fewer than 2 percent of the cancer patients they’re aimed at.”
A transcript of that conversation appears here.
In our conversation, Prasad said the percentage of patients likely to benefit is actually two-and-a-half times higher than that. The newspaper “should have just used our paper in JAMA Oncology, where we estimate genomic drugs to be 9 percent, 5 percent responders, I think that is a better estimate, for that particular quote that they’ve used.”
Asked to explain the origin of the 2 percent estimate, Prasad said:
“It depends on the question you’re asking. If the question you’re asking is, of all the people with relapsed tumors who go on NGS, then the answer is two percent. If the question you’re asking is, of all the de novo cancer patients in America who may benefit from a genomically-targeted drug, the answer is about 5 percent, and that’s our estimation paper in JAMA Oncology that came out last month. I think there are two different estimates. I think these numbers are much lower than what I think many would suspect them to have been. I think they are sobering.”
To put this in perspective, I bounced this comment off MSKCC’s Hyman, Prasad’s debate opponent at AACR.
“This analysis draws an artificial distinction between genome ‘targeted’ and ‘informed’ therapy,” Hyman, a gynecologic oncologist said. “BRCA-mutant breast and ovarian cancer patients who achieve ~60 percent response rates with PARP inhibitors might be surprised to learn they are not benefiting from ‘targeted’ therapy by this definition.
“Response rates, according to RECIST, were also never intended to strictly define the proportion of patients who benefit. An ALK fusion lung cancer patient with a -25 percent tumor regression (stable disease per RECIST), lasting >3 years probably feels like they have benefited from targeted therapy.
“Ironically, this author has separately published critiques on use of response rate as a ‘surrogate endpoint’ for patient benefit. Instead, I believe this analysis suggests that ~16 percent of advanced cancer patients currently qualify for proven and routine genome-driven therapy.
“Moreover, this estimate does not account for investigational therapies the patient may qualify for on the basis of this type of testing.”
The 2 percent treatment rate cited in the Prasad paper and in the Times editorial came from an early interim analysis of the NCI MATCH trial, for patients with advanced disease. Reported in 2016, these data came from the first 645 patients screened for ten arms that were open at that time, all targeting rare variants. Today, the trial has 35 arms.
“After accrual of nearly 6,000 patients to the centralized screening phase of the MATCH trial, we found that 19 percent of patients had molecular findings that permitted treatment assignment,” said Keith Flaherty, director of Clinical Research at the Massachusetts General Hospital Cancer Center, professor of medicine at Harvard Medical School, and the ECOG-ACRIN chair of the NCI MATCH trial. “Notably, this excludes the proportion of patients who were not eligible for treatment assignment in MATCH because of prior FDA approval or ongoing late stage trials in patients with those cancers types with those same molecular features. Our experience indicates that NGS testing was an efficient strategy for identifying patients for inclusion in MATCH.”
Zeroing in on Prasad’s “thought experiment”
My conversation with Prasad zeroed in on another of his papers cited in the Times, the “Comment” in the May 18 issue of Nature Reviews Clinical Oncology.
Again, our discussion, which can be read in transcript, triggered profound confusion on my part. A reader is free to blame me, but the fog was failing to lift.
Here is how Prasad’s commentary was described in the Times:
“Drug approval has become so lax and relatively inexpensive, one recent study suggested that companies could theoretically test compounds they know to be ineffective with the hope of getting a false positive result that would enable them to market a worthless medicine at an enormous profit.”
Running trials of compounds that the sponsors know to be ineffective would be diabolical on many levels.
While Prasad’s paper didn’t suggest that this was actually happening, it claimed that it was feasible, i.e. that drugs cost so much that a pharmaceutical company could turn statistical errors into profits.
Prasad told me that he was quite proud of that publication, continuing to describe it as a “study.”
“I think a thought experiment is a type of study, it’s a thought study,” Prasad said to me. “In certain fields, some of the studies are purely thought experiments. I think it’s a very clever paper. I guess at the end of the day, I think that’s a good paper. It’s a very good paper, it’s a very clever experiment, and I haven’t heard anyone articulate anything they think is fundamentally wrong with that thought experiment that would change the conclusion.”
Clearly, Prasad is not alone in seeing value in this thought experiment.
Diana Romero, chief editor of Nature Reviews Clinical Oncology, wrote in an accompanying editorial titled “To all involved—we have a problem” that the comment by Prasad and collaborators Christopher McCabe and Sham Mailankody represented more than a “moaning exercise” about drug pricing:
“Their conclusion is sobering: any anticancer drug that generates a US$440 million profit and is approved on the basis of the results of a single clinical trial would justify a hypothetical portfolio involving 100 inert compounds.
“This scenario is an exaggerated distortion of reality, and the authors ‘certainly do not believe that companies are actively pursuing ineffective drugs’, but the revenue they propose actually matches those of many agents currently used in clinical practice.
“Let’s not forget that anticancer agents remain the best-selling drugs among FDA-approved therapies (32 percent of sales projected in 2017)2. Another fact to keep in mind is that many drug approvals are indeed based on the results of a single trial, which do not always meet the threshold for meaningful clinical benefit3.
“[The authors] state that the risk–benefit balance in oncology clinical trials (regardless of whether they are intended to lead to drug approval) remains to be properly addressed. They do not explicitly formulate a request but, after reading their article, we cannot help but ask for transparency from the regulatory bodies regarding the criteria they use for drug approvals.”
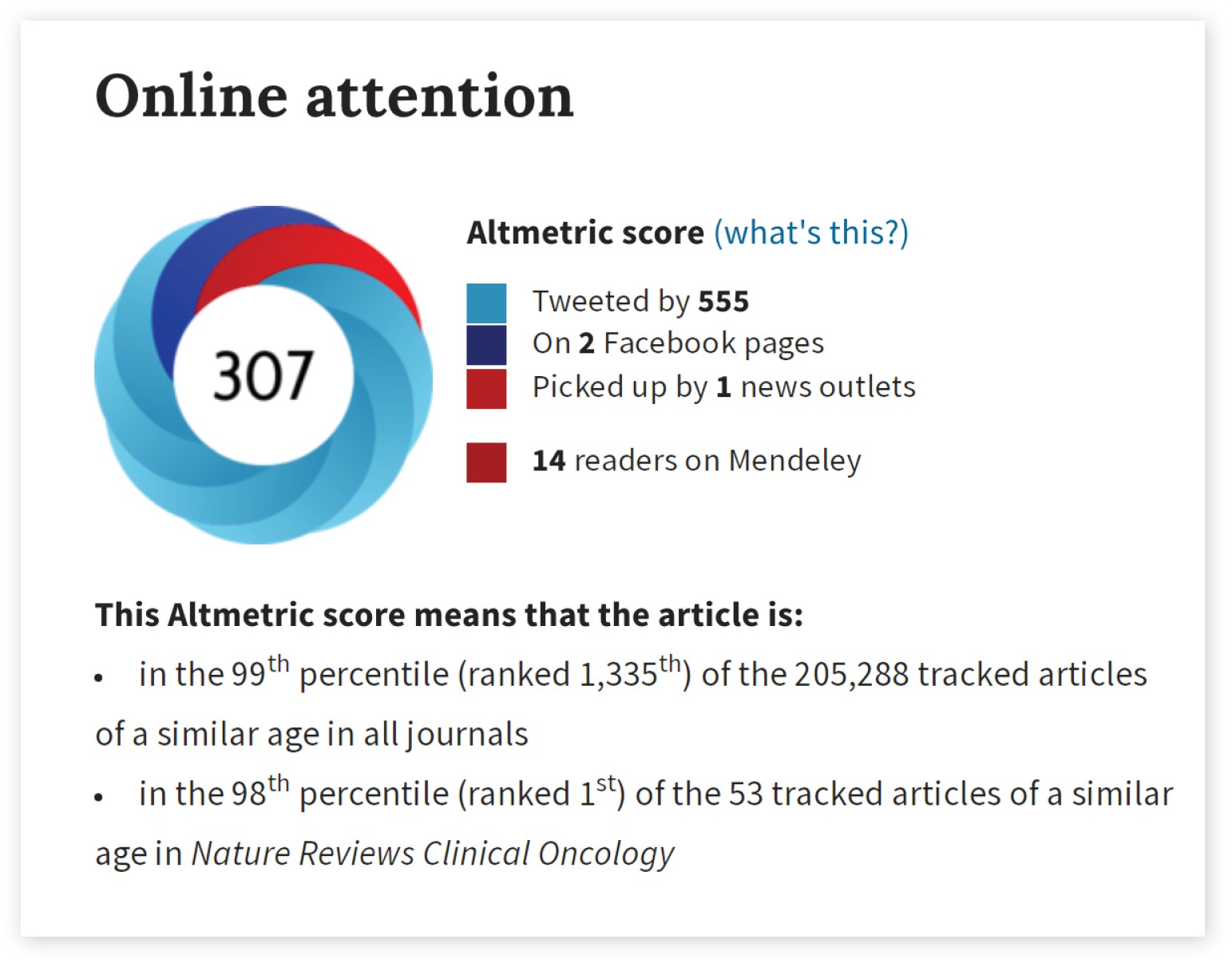
The article’s usage metrics, Altmetric score of 307, places it in the top spot among 53 tracked articles of a similar age in Nature Reviews Clinical Oncology. Overall, the paper is in the 99th percentile of tracked articles of a similar age in all journals. The thought experiment was tweeted by 555 and picked up by one news outlet—the Times.
After reading the paper, I had questions about the methodology that went into it.
My biggest question was about the p-value Prasad and his colleagues used in the calculation.
They said that they used a p-value of < 0.05 for how often the inert compounds at the center of their thought experiment would appear beneficial by chance alone. Then, they based their calculations on this p-value equating to the inert compound seeming beneficial by chance 1 in 20 times.
This seemed both like very basic statistics, and utterly wrong. Testing two things that are the same against one another will lead to one or the other looking better 1 in 20 times by chance, which means the drug they were hypothetically testing would only look better 1 in 40 times.
When I asked Prasad about this, he told me that their p-value was one-sided—something never mentioned in the publication. And it’s not something I have ever encountered in decades of covering FDA.
Other questions about why he left out some costs of testing a drug were answered in equally baffling ways. Why didn’t he adjust for inflation when using old estimates of how much a clinical trial cost?
I couldn’t follow these answers, and I assumed the readers of The Cancer Letter would also be left more confused than enlightened. So, I decided to borrow a technique routinely used by journals—I put the paper through a process that largely mimics peer review.
First, I wanted to check whether the “thought experiment” had been subjected to peer review at Nature Reviews Clinical Oncology.
“Comment pieces in Nature Reviews Clinical Oncology are topical, authoritative Op-Eds pertaining to scientific research and its ramifications,” Rebecca Walton, a spokeswoman for Nature said to me. “Comment pieces do not typically undergo formal external peer review, but are carefully edited by our in-house professional editors, and undergo fact-checking and copyediting. For confidentiality reasons, we cannot discuss the specific history of any published article with anyone other than the authors.”
Translation: Not as far as we know.
Peer review is a sacred area in science. I didn’t want to do anything that might seem unethical or unreasonable.
Perplexed, I called Art Caplan, the Drs. William F. and Virginia Connolly Mitty Professor of Bioethics at New York University’s Langone Medical Center, an expert on ethics in medicine and medical publishing.
I asked Caplan to assess my nascent plan for assessing the value of Prasad’s thought experiment. Of course, this would not be formal peer review, but rather a process resembling peer review of the science at the heart of an already-published opinion piece.
“Editors do review opinion pieces, but it doesn’t make it a study,” Caplan said. “In peer review, you are given the assignment to make sure the methods justify the conclusion. In an editorial opinion piece, normally the editor is asking: ‘Is this coherent? Does this argument seem to hold together? But that’s it. They are what I would call ‘vetted,’ but they are not studies. Signals like ‘comment,’ ‘editorial,’ ‘opinion’ are what journals use to say this is not a study. It could be based on reading other articles and offering your view and interpretation, but it doesn’t make it a study.”
I told Caplan that as a reporter, I prefer to keep my sources on record as much as possible, though sometimes I work with unnamed sources. In this case, potential referees told me that they preferred to submit comments confidentially, citing concerns about being accosted on social media.
“I think you can run with anonymous review; I have no issue with that whatsoever,” Caplan said to me. “I have no issue with that, because you know who the reviewers are, you can say the reviewers requested anonymity, you say the reviews are worth publishing, you will be the object of the tweets, and so what? A lot of peer review operates in exactly this way, with anonymous referees. A lot of reviews I get say Referee 1, Referee 2, Referee 3, and I have to trust the editor to have made a selection of reasonable reviewers, because I have no idea who they are.
“Go ahead, these are important matters of policy.”
I decided to keep the authorship confidential, and to publish the critiques. After that, I submitted the critiques to Prasad and his co-authors, and asked one of the reviewers to assess the responses.
I did this with full realization that some journals are starting to move away from anonymous review. However, anonymous review is used by the vast majority of journals.
The assessments of the three reviewers speak for themselves.
The three reviews
All three reviewers agreed with the question I raised about the two-sided p-value. They also pointed out that:
The thought experiment fails to account for the costs of phase I and phase II trials.
Also, Prasad et al. seem to confuse revenues with profits, in essence assuming that it costs nothing to run a pharmaceutical company.
The full text of the reviews—with responses from Prasad and his colleagues—appears here.
Here are excerpts from what the reviewers said:
Reviewer 1: Drug profits would… need to be well-north of $2.5bn per drug to justify development of ineffective agents, about 6-fold the authors’ estimate… Maybe we need more transparency about the criteria for drug approval and a suitable, informed debate might well be enlightening. Simplistic, headline grabbing arguments, on the other hand, are not of value.
Reviewer 2: The authors are wrong on what the p<0.05 reflects regarding how often a trial of an inert compound would be ‘positive’. They repeat this same error when they talk about the probability of having two falsely positive trials listing it as .05^N. They say one in twenty trials would by chance alone be ‘positive’. What they clearly mean is that one in twenty trials would show the inert compound to be superior to the comparator. This is a big oops. In testing the null, setting the p cutoff to 0.05 is equivalent to saying you would accept a ‘falsely significant’ finding (i.e. a Type 1 error) one in twenty times, but those occur half the time when the inert compound appears better than the comparator by chance, and half the time when the opposite is observed by chance. In other words the B term is half the value it should be.
Reviewer 3: Accepting a single trial with a p-value <0.05 means there is less than a 5 percent probability the finding is wrong due to chance. It is not a 5 percent chance the drug is ineffective or there is a false positive. These are slightly different things that I believe the authors confuse. I am also concerned that lumping 100 trials of different drugs, each with a p<0.05 and assuming 5 findings will be wrong is inappropriate. I am sure that assuming 5 findings will be a false positive is a stretch.
In statements about the cost of drug development and the money made selling an approved drug:
I worry the authors confuse a drug company’s revenue with a drug company’s profit.
I do note a single phase III trial is estimated to cost $22.1 million in what year? The cost to a drug company for drug development is not just the phase III costs. Is it appropriate to say these costs are “sunk?”










