A collaboration of 10 healthcare research organizations has demonstrated that real-world endpoints can be used to describe patient outcomes that are analogous to results generated through conventional endpoints in clinical trials.
The effort, drawn in part from data contributed by health IT companies with oncology portfolios, is the most recent phase of a three-year pilot study led by Friends of Cancer Research. At a virtual conference Sept. 21, Friends announced the conclusions of this phase of the project.
The project focuses on outcomes for real-world patients with non-small cell lung cancer who received immune checkpoint inhibitors. In this phase of the project, researchers assessed the utility and validity of real-world endpoints across three NSCLC cohorts—patients who received platinum doublet chemotherapy, PD-(L)1 monotherapy, and PD-(L)1 + doublet chemotherapy. These real-world patient outcomes were then “benchmarked” against clinical trial results.
“We call this the results of an analysis using Pilot 2.0 data, with 10 of our data partners, who have performed these analyses for today’s discussion,” Jeff Allen, president and CEO of Friends, said in the conference.
The results of the analysis show that the magnitude of benefit obtained from immuno-oncology treatment regimens in the real world—i.e. measured via real-world overall survival and time to treatment discontinuation—is directionally similar to outcomes in a conventional clinical trial.
The groups taking part in this phase of Pilot 2.0 are: ASCO CancerLinQ/ConcertAI, COTA, Flatiron Health, IQVIA, Kaiser Permanente/Cancer Research Network, Mayo Clinic & OptumLabs, McKesson, SEER-Medicare Linked Database, Syapse, and Tempus. FDA and NCI served as key advisors.
“The goal is to establish some standards that you can use to compare across different definitions and different methodologies,” Jonathan Hirsch, founder and president of Syapse, said to The Cancer Letter. “It’s important that when you are rigorous about your definition, your structure and your methodology for doing the analysis, you can actually come up with a result in the real world that is trustworthy, that’s comparable to the clinical trial, and then comparable across different datasets.
“Kudos to the Friends crew. I mean, if you could look at what Jeff and his team has managed to do, given the circumstances these past six months, they really kept everyone focused and on task. They are just knocking this out of the park.”
The results announced this week build on earlier phases of the project, which had previously achieved two objectives:
In 2018, Pilot 1.0 concluded that it was possible to identify a high level of shared characteristics across varying datasets—demonstrating that it is feasible to extract data about specific patient populations from disparate sources of data.
In 2019, in the early stages of Pilot 2.0, the data groups developed a set of common definitions for real-world endpoints—including real-world overall survival and progression-free survival—and other non-traditional endpoints that have the potential to serve as proxies for conventional endpoints.
For a deep-dive into the earlier phases of the project and the statutory context for developing RWE that is fit for the regulation of therapeutics, as well as the market forces driven by investment from pharmaceutical companies, read The Cancer Letter‘s 2019 coverage, which includes interviews with project leaders at Friends, NCI, and 10 of their data partners (The Cancer Letter, Nov. 22, 2019).

The COVID-19 application
Frameworks of this sort are becoming increasingly important to public health strategy, as the COVID-19 pandemic forces regulatory authorities worldwide to rapidly develop a real-world data infrastructure to derive insights and speed up the approval of novel treatments.
“Enter March and COVID-19, where we realized we had a massive number of questions to answer, and a new data infrastructure from which we could draw, like electronic health record data, or EHR married with claims data, and other activities, but really not the preparations in place to figure out how we were going to leverage real-world data and put it to task for COVID-19,” Amy Abernethy, principal deputy commissioner and acting chief information officer at FDA, said in the virtual conference.
“We acknowledged that we were going to need to do that quickly, while also maintaining a clear eye to the importance of getting the science right. So, how do we make sure that the data are fit for purpose? Do we know the right analyses and have the analyses fit for the purpose of the tasks at hand?” Abernethy said. “And we understand the questions that can be answered with real-world data in the context of COVID-19 are essentially the use cases.
“So, in March, at FDA, we were really trying to figure out how we were going to do this work quickly, and looked to our partners in the Reagan-Udall Foundation and Friends of Cancer Research.”
During the Sept. 21 conference, Allen said researchers were able to:
Identify a similar directionality in treatment effect of IO as compared to chemotherapy in RWE consistent with findings in recent clinical trials.
Demonstrate correlation between real-world OS and other real-world endpoints, including in datasets with near complete mortality data—indicating the potential use of real-world Time to Treatment Discontinuation (rwTTD) and real-world Time to Next Treatment (rwTTNT) as a proxy endpoint for treatment effectiveness in real-world studies.

The questions used to guide this phase of the project were:
Can real-world endpoints be used to accurately characterize differences between available interventions?
Can further alignment on data quality and standards be used to develop an analytic framework to evaluate real-world endpoints?
The answer to these questions, according to the collaboration, is a definitive “Yes.”
Over three years, researchers were able to 1) describe the demographic and clinical characteristics of aNSCLC patients treatment with immune checkpoint inhibitors, 2) assess the feasibility of generating real-world endpoints in the selected patient cohort, and 3) assess the performance of real-world endpoints as surrogates for conventional endpoints i.e. OS.
Results of NSCLC analyses
There are three takeaways from the scrubbed data:
Overall survival: NSCLC patients who were treated with IO agents in the real world have higher 12-month OS compared to patients who received chemotherapy-only treatment. This is consistent with outcomes data generated through conventional clinical trials.
Time to Next Treatment: Patients receiving IO therapy in the real world may be staying on the treatment regimen longer than those receiving only chemotherapy—likely an indication that their cancer has not progressed.
Time to Treatment Discontinuation: Similar to the TTNT data, patients on IO regimens in the real world were less likely to discontinue treatment at 12 months, compared to patients on chemotherapy-only regimens.
A detailed discussion of these results by Allen appears at the end of the story.
The pilot project isn’t over. There are myriad challenges—generating high-quality data, and then harmonizing across several datasets is a labor-intensive process that requires unprecedented methodological rigor.
Also, the framework isn’t a shoo-in for using the real-world endpoints defined herein to approve new therapeutics. Neither does the stepwise validation of real-world endpoints mean that they would replace conventional endpoints or randomized controlled clinical.
“This doesn’t, in and of itself, fully validate the real-world endpoints, in that all the different data providers have different datasets that they have access to,” Syapse’s Hirsch said. “They have different ways of cleaning up the data. There’s still a little bit more work to do to get to full comparison and full validation, but this is a really important step to basically be able to demonstrate that there’s a trustworthy element to these sorts of analysis. So, there’s a lot of progress.
“I think the important thing, though is, or one of the important things to make sure to point out is it’s not like none of this is to say that the results in the real world are always going to be equivalent to the clinical trials because the populations are different.”
Nevertheless, with these results, researchers are one step closer to understanding how real-world endpoints may be used for regulatory purposes, Hirsch said. The next step would be to identify which real-world endpoint would be a good proxy for OS, and, perhaps, PFS.
“The goal here is clear, which is to keep on establishing methodological rigor to use real-world data for regulatory purposes,” Hirsch said. “And this is a very good step in that direction to establish trust and credibility in this area. So, definitely one step closer.”
Novel endpoints
Conspicuously, some of the endpoints used in the analysis—rwTTD and rwTTNT—aren’t typically used by clinical trialists. Would FDA consider adding these endpoints to its regulatory armamentarium?
“These are endpoints that we have used in the past in clinical trials,” Sean Khozin, global head of data strategy at Janssen R&D, Johnson & Johnson, said at the Sept. 21 conference. “But because we can precisely measure [endpoints like] progression-free survival, we start to imagine TTD and TTNT, which were endpoints that did emerge from the world of clinical investigations.
“I think it’s important for us to keep that in mind, and to, in fact, look at these endpoints in traditional clinical trials, so that we can have a benchmark in terms of the modified endpoints that we’re deriving out of real-world data,” said Khozin, formerly associate director of the FDA Oncology Center of Excellence, and the founding director of Information Exchange and Data Transformation (INFORMED), the agency’s first data science and technology incubator. “Benchmarking what we do and how we do things in traditional clinical trials is critical to optimizing how we use and how we analyze real-world data.
“When we say optimization, that means we have a gold standard in mind. And if that gold standard is traditional randomized clinical trials, it’s important to establish where that bar is—when it comes to the integrity, when it comes to endpoints, for example TTD and TTNT—in traditional clinical trials.
“In fact, some of those standards and parameters haven’t yet been defined. So, there is an opportunity right now to look at how we do things in clinical trials; try to establish quantitative benchmarks that we can then carry over as we optimize the use of real-world data.”
Testing the framework in melanoma in France
In a related project—Pilot 3.0—Friends collaborated with Owkin, Centre hospitalier universitaire de Nantes (CHU de Nantes), and Réseau National sur le Mélanome (RIC-Mel) to apply the framework generated through earlier phases to real-world datasets for patients with melanoma.

“It was very interesting to use another setting and see how the framework could be transposed,” said Maxime He, a data scientist and team leader at Owkin, a company headquartered in New York City that uses machine learning and artificial intelligence to generate predictive models and healthcare solutions.
“So, we came along, we took the framework, and then we got to work, applying it to melanoma patients in France,” He said to The Cancer Letter. “The objectives were met. In our experiments, we could establish exactly the comparisons as well—for instance, using endpoints such as time to treatment discontinuation as a proxy. The real-world and experimental were quite comparable. There were no inconsistencies.”
He presented the Pilot 3.0 results in the virtual conference Sept. 22.

“And, on the correlation side of things, to assess the proxy potential of endpoints, we saw they were quite correlated, and better yet, it seemed that the correlation between time to treatment discontinuation and overall survival was of the same magnitude—between their setting with the non-small cell lung cancer and our setting with melanoma patients, indicating that this correlation is quite robust, which is a very good signal.”

FDA has been very proactive in helping to move the project forward, He said.
“They are the regulator. They could sit back and look at things and wait for them to mature, but really, that’s not the kind of strategy that they’ve shown, at least to us,” He said. “Scientifically, the pilots are only going to get more interesting. The real-world is really appropriate for AI deployment and use. And, for example, we are particularly working on synthetic control arms at Owkin.
“Actually, in our experiments, it’s showing that using AI in the control arms is really an improvement over traditional statistical methods. So, we’re really excited. We would be really excited to get involved with more scientifically and methodologically advanced pilots.”
An excerpt from Allen’s remarks at the Sept. 21 virtual conference follows:
In order to move into the results that we’ve observed, this slide depicts the percentage of overall survival at 12 month by treatment type. As you can see, and looking at the observations from each of the different groups denoted by letters at the bottom axis, there is a proportional improvement that is suggested among several of the datasets, when looking across the different treatment options.
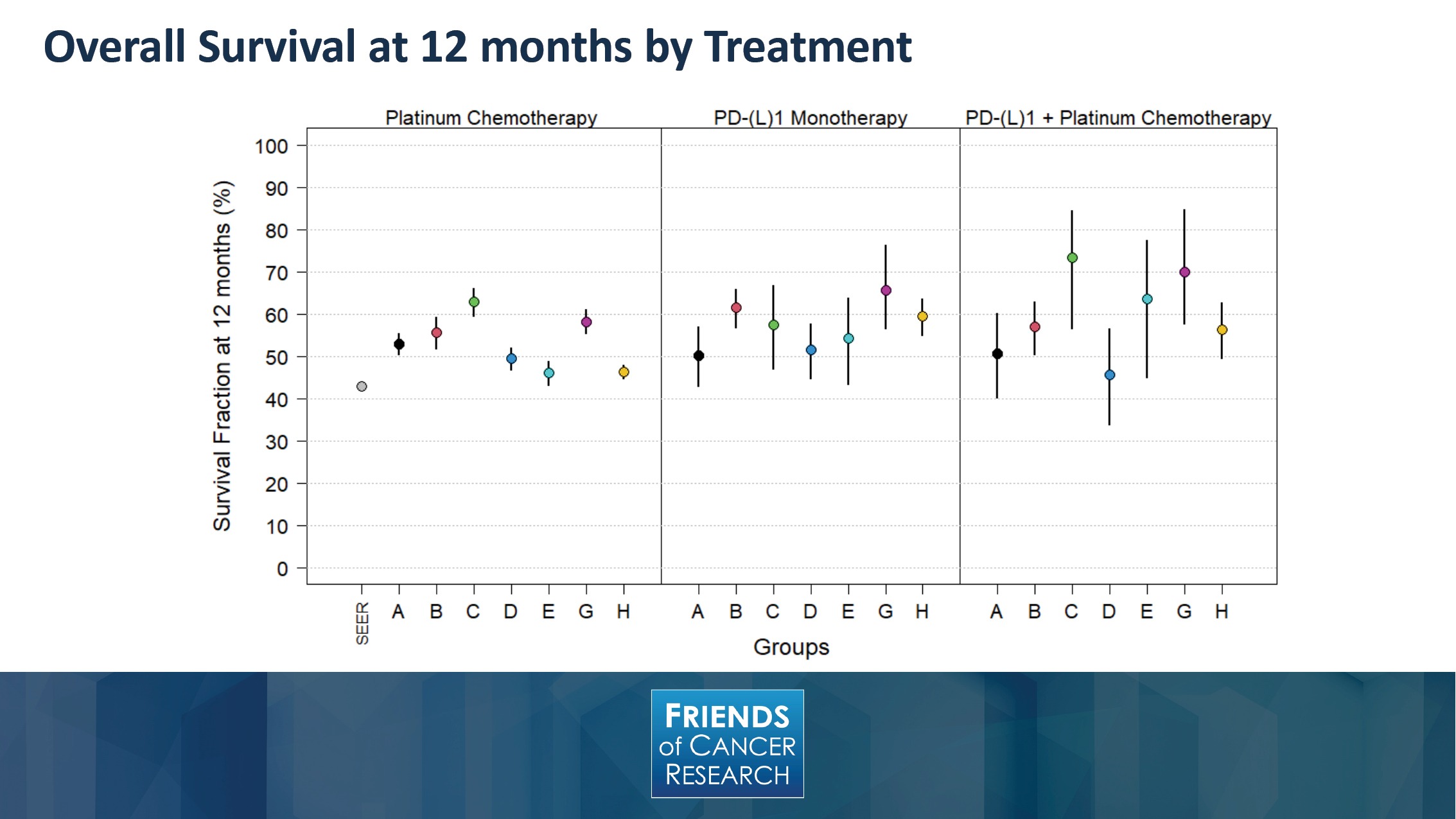
It is interesting to note, when looking at overall survival, in other objective endpoints, these are susceptible to post-baseline events like subsequent therapies, and may make the treatment effects harder to interpret.
It may also suffer from substantial missing mortality data, incomplete follow-up time, and patient crossover. These are all reasons that could contribute to variation between the different datasets and make overall survival a challenging endpoint, at times, to definitively assess between these different treatment options.
Nevertheless, what can be seen here is the directionality of an IO treatment effect was demonstrated in the real-world results. While there’s a wide range of estimates across datasets, those with IO included tend to have a higher 12-month overall survival than chemotherapy-treated patients—though you can note that there is overlap between the confidence intervals.
On the far left hand side of the graph, you can see the SEER dataset, which is identified and provides a population-based reference. It should also be noted that the SEER data is based on Medicare, so it has no younger patients, whereas several of the participating groups had over a third of their patient populations younger than those that might be captured within the SEER data.
Other population differences weren’t controlled for as well, such as differences of staging that might be seen within the population.
On the right-hand side, it’s worth noting that the smallest number of patients are in the IO-doublet group, and this contributed to the broader confidence intervals that you can see around each dataset. This, in large part, is due to the recency of time that IO and doublet therapy was adopted into routine clinical care.
As a measurement of Time to Next Treatment, this slide depicts the fraction of patients who have not started a next treatment within 12 months.

Here you can see that TTNT shows a more definitive trend toward increasing, for IO-containing treatments. This may be an indicator that patients are staying on their treatment longer, because their cancer has not progressed. Though, it should be noted that TNTT is a challenge as an endpoint, if a treatment is on a fixed number of cycles.
Again, on the left, you can see that the SEER dataset is noted as a benchmark, and it should be noted that, on the right hand side, the Group C information was dropped due to incomplete follow-up time for the doublet treatment regimen.

Similar to what was observed with TTNT, this slide depicts the measure of Time to Treatment Discontinuation, by demonstrating the fraction of patients who have not discontinued treatment at 12 months.
As a reminder, TTD was defined as having a subsequent therapy, 180 days without therapy, or a date of death while on a frontline therapy.
A similar trend toward TTD for patients treated with IO-containing regimens was observed. Some of the variation that’s seen between the different datasets may occur based on the source of the data.
For example, with claims data, the data may be more longitudinal, which could take more time in order to show a discontinuation event, whereas EHR data could be more rapid.






